きっかけ
前回、サンプルアプリを作れそうなことがわかったので、実際にアプリを作ってみることにした。
案
せっかくなので今週の読売新聞の特別面に載ってた「平成300の顔」という企画をモチーフにしてみた。
※企画的には平成を10年ずつにわけて、それぞれを代表する100人を集めたような感じっぽい。
平成時代もあとわずかですが、本紙の記者たちがこの30年間のニュースから「平成300の顔」を選んでみました。今日28日の朝刊では平成前期(元年~10年)の100人を紹介しています。写真の顔は誰か、皆さんはどのくらい分かるでしょうか。
— 読売新聞 編集委員室 (@y_seniorwriters) 2019年4月28日
29日は平成中期、30日は平成後期の100人を掲載します。お楽しみに pic.twitter.com/ZRXvKfjjtf
写真をみても知らない人もいて、答えを見たりWIKIで調べたりしたのをもちっと簡単にできたりするといいかなって思ったので
せっかくだからアプリ化してみるかと。
なので、アプリ的には
・対象が300人の中からランダムで1名抽出
・顔写真を表示されている
・何かをすると解答が表示される
あたりの機能を想定。
作成開始
とはいえ、右も左もわからないのでこちらを参考に。
※ただ、ちょいちょいわからなかったので、Guthubのと見比べたほうがよいかもしれない
https://github.com/kozake/my-awesome-ionic-app/blob/master/src/app/components/beer/beer.component.ts
上記を参考にいったんサンプルとして作り、アプリの仕組みをなんとなく理解したうえでアプリ的に必要そうな機能を実装していく。
Typescriptもangular.jsも触ったことなかったけど、雰囲気はつかめた気がする。
class
ionic generate class models/beer
クラス作成(MVCでいうところのModelと理解)
ここで使いたいデータの[クラス]を定義する
なので、以下を作成し、名称、画像URLあたりを定義するようにする。
ionic generate class models/person
component
ionic generate component components/beer
コンポーネント作成。バーシャルViewみたいなものか?
なので、以下を作成し、画像を表示する処理を追加
ionic generate component components/person
回答ボタンを押下したら、名称が表示されるようにする機能とリロード機能を実装
service
ionic generate service services/beer
これもMVCだとModelに近いような気がする。
classを生成するためのモジュールみたいな使い方になるのかな。
ionic generate service services/person
人数分のデータを生成、ランダムで取得される機能を実装
画像収集
ここまででひとしきり必要な「機能」はできた。
が、実際のデータがない。
300人の名称については、読売オンラインあたりにあるかと思ったが、それもなかった。
まあ、名称については新聞に記載しているものを転記すればいいのだが、
表示するための画像については悩んだ結果、とりあえずGoogleさんに頼ることにした。
画像そのものではなく。画像のURLが欲しいだけなので以下を作ってみた。
import pandas as pd
df = pd.read_csv(r"C:\PJ\02_app\20190430_H300Face\list.txt", encoding='shift_jis')
from urllib import request as req
from urllib import error
from urllib import parse
import bs4
def p_image(keyword, count):
urlKeyword = parse.quote(keyword)
url = 'https://www.google.com/search?hl=jp&q=' + urlKeyword + '&btnG=Google+Search&tbs=0&safe=off&tbm=isch'
headers = {"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:47.0) Gecko/20100101 Firefox/47.0",}
request = req.Request(url=url, headers=headers)
page = req.urlopen(request)
html = page.read().decode('utf-8')
html = bs4.BeautifulSoup(html, "html.parser")
elements = html.select('.rg_meta.notranslate')
import json
jsons = [json.loads(e.get_text()) for e in elements]
imageURLs = [js['ou'] for js in jsons]
# imageURLs
for index, url in enumerate(imageURLs):
print("'{}',".format(url))
if(index >= count):
break
for index, row_key in df.iterrows():
print("new Person('{}', '{}', '{}',".format(str(index+1), row_key["name"], row_key["katagaki"]))
key = "{}".format(row_key["name"])
p_image(key, 1)
key = "{},{}".format(row_key["name"], row_key["katagaki"])
p_image(key, 1)
print("false,''),")
雰囲気はわかると思うが、キーワードで画像検索して、その中の[rg_meta.notranslate]の[ou]に入っているURLを使っている。
で、その結果をそのままファイルに食わせ、それをserviceでインスタンス化?させて、そのうち一つだけを画面に表示させて、出来上がり。
完成
半日ぐらいで出来上がり。
仕組みそのものはかなり簡単。
どうやって画像収集するか、どうランダムに表示させるか、300人分の転記あたりには時間がかかったけど
そういコンテンツに関する部分に対して時間をかけることができるっていうのはいいフレームワークだと思う。
リリースビルドやストアへの公開はなんかさらにめんどくさそうだったので今回はとりあえず割愛
デバッグビルドのapkをFireHD10へコピーしてインストールして遊んでみた。
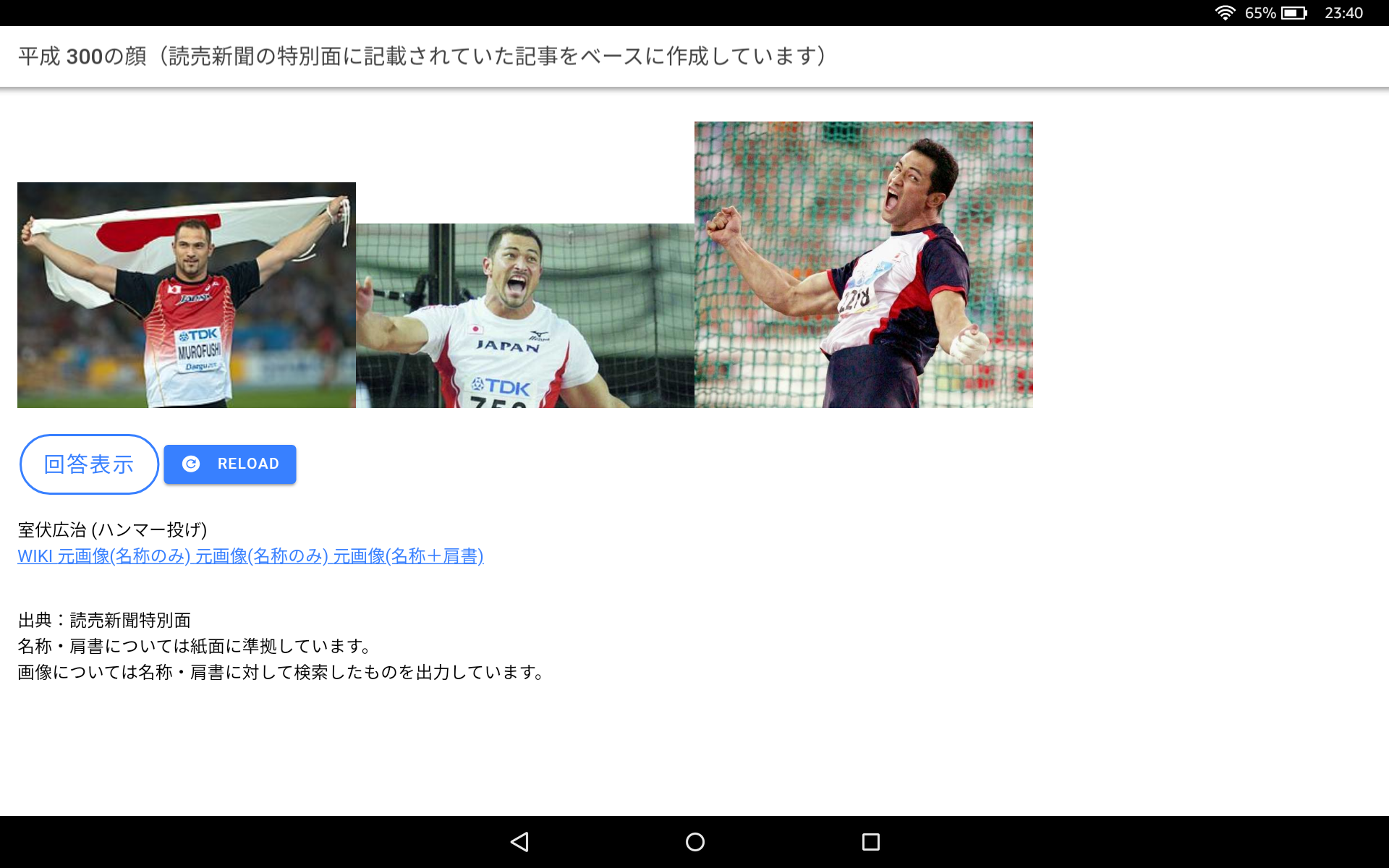
こんな感じ。
もっといろいろな機能を入れてみたいとは思うが、とりあえずは「アプリを作ってみたい」というのが目的だったので、いったんこれで満足としておく。
https://github.com/RyoNakamae/SampleApp
<デバッグビルドでのapk>
https://drive.google.com/open?id=1uk3TuWjz5G4Dt-r8Ad1I9YvwoX4-_3kb
上記に置いてあるので、遊んでみたい方はどうぞ。