ただの集団 Advent Calender PtW.2019の8日目の記事です。
昨日は、kanoka9さんのETLにAWS使う場合の選択肢でした。
はじめに
最近自然言語処理周りのタスクをやっています。自然言語処理でいろんな基盤技術が存在しています。形態素解析、構文解析、固有表現抽出などなど。このような細かい分野によくある手法を調べたとき、割と数式多いの記事が多い気がします。
初心者として新しい領域で手法を調べる時、いろんな数式を理解しないといけないことは結構挫折を感じます。
また、入門する時とかプログラムを動くだけ良い時とか、別に数式の詳細を詳しく知る必要がないと思います。ニーズによってどんな流れで処理するとかどうやって使うとかの全体像を理解すれば良いと思います。
今回は固有表現認識でよく使われるBi-LSTM-CRFの全体像を数式使わずに説明します。
対象読者
- NLPを少し知っている方(word embeddingとtokenを知るくらい)
- ニューラルネットワークを少し知っている方(勾配、sigmoidを知るくらい)
固有表現認識とは?
固有表現認識はテキストの中に出る固有名詞(人名、地名、組織名など)や日付時間など固有表現を認識する技術です。英語はNER(named entity recognition)に呼ばれています。
例としては
太郎は1989年に東京で生まれた
から、NERタスクは人名として太郎、日付として1989年、地名として東京を抽出します
LSTM(Long Short Term Memory)とは?
LSTMはリカレントニューラルネットワーク(RNN)の特別な一種です。なので、LSTMを紹介する前に、RNNを若干説明します。
リカレントニューラルネットワーク(RNN)とは?
RNN(Recurrent Neural Network)は、日本語でよく循環ニューラルネットワークと訳されます。個人的に、循環ニューラルネットワークという呼び方より記憶があるニューラルネットワーク方がイメージしやすい。
単語推定を例として説明します。
例えば、
太郎は1989年に東京で生まれた。__語を喋ることはもちろん
で空白にいる単語を推定するタスクがあります。空白にいる単語はもちろん日本なんですけど、ニューラルネットワークから予測すると、重要な文脈として東京は把握することが必要です。一つの考えとしては文脈をニューラルネットワークに保存します。
RNNはこういうニューラルネットワークです。
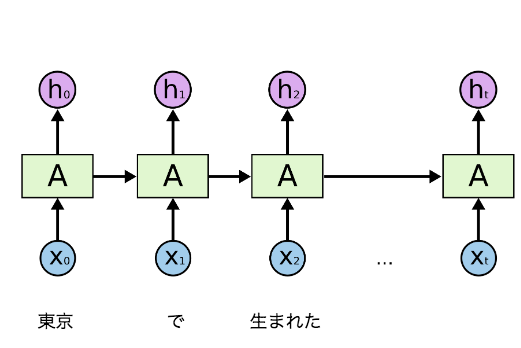
上の図で、入力はxtで、値htを出力します。
前ステップの情報は次のステップに渡すなので、文脈を把握することは可能です。
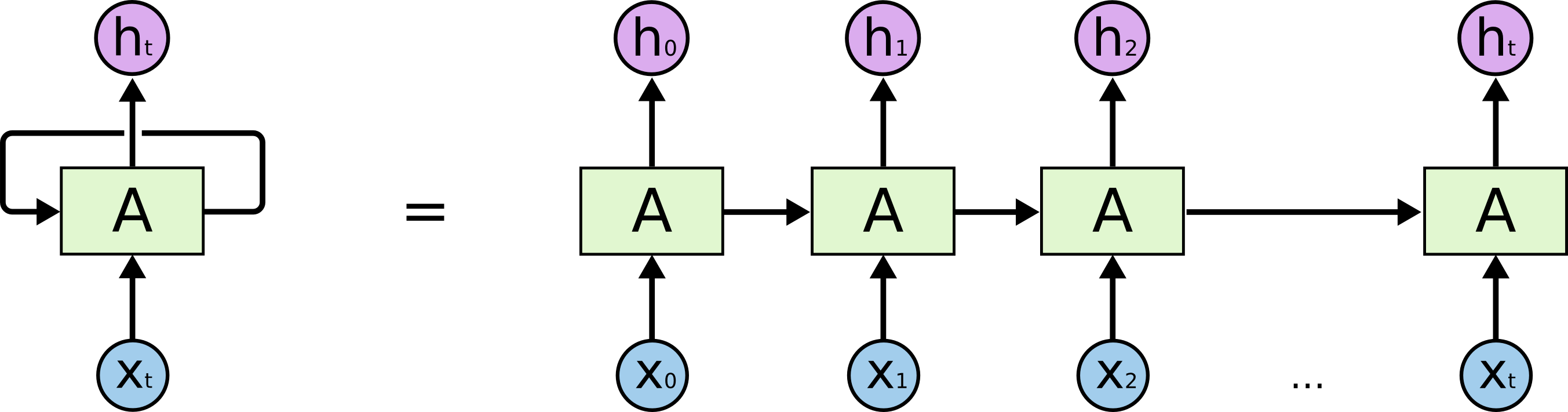
また、このニューラルネットワーク構造を一つにすると、こういう構造になるので、前ステップの出力は次のステップの入力に加えてx、ループ構造を持つため、循環ニューラルネットワークとしても理解できます。
RNNの問題点
このような単語推定をどうやって考えてみます。
次郎は1989年に東京で生まれた。兄弟五人。兄は太郎。また弟二人があります。三郎、四郎と呼ばれています。__語を喋ることはもちろん
今回もRNNで使えると思うけど、今回の重要な文脈東京は予測したい単語の間の距離が遠いので、RNNも使えるけどレイヤ数は増えます。ただ、レイヤを増えると、過去の勾配はだんだん弱く(勾配消失)になってしまうので、ほぼ情報を持たなくなってしまった。
LSTMとは?
先の例でRNNの問題としてはニューラルネットワーク機能の不完全です。重要な単語を忘れてしまい、重要ではない単語を覚えるになります。直感で覚えべき単語だけ覚えて、重要ではない単語を話すれば良い。まさにLSTMの考えです。
Long Short-Term Memoryネットワークは、よくLSTMと呼ばれ、先ほどRNNの問題点に対応できる、RNNの特別な一種です。
LSTMは「ゲート」という仕組みを導入されています。Inputゲート、OutputゲートとForgetゲートでメモリに保存すべきものをコントロールします。
RPGゲームを例として考えてみよう!
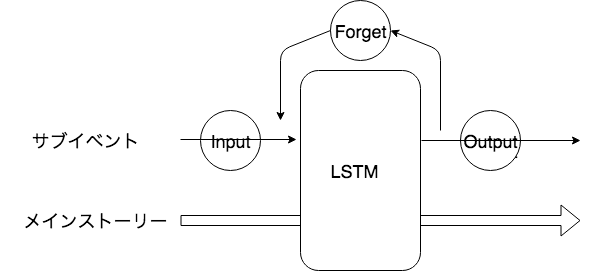
全体をコントロールメモリがあるため、メインストーリーとして考えてみます。もともとのRNN体制をサブイベントとして考えてみます。
- Input
- 今のサブイベントはEndingに重要であれば、Inputコントロールはこのサブイベントを重要程度によって、メインストーリーに書き込みます。
- Forget
- 今のサブイベントは前のメインストーリーの考えを変わりまして、Forgetコントロールはメインストーリーの一部を忘れて新しいメインストーリーに書き換えます。
- Output
- Outputコントロールは現在のメインストーリーとサブイベントの状況を判断してアウトプット内容を決めます
固有表現認識とBi-LSTM
自然言語処理タスクでRNNでもLSTMでも左から右に入力しています。
この特性は自然言語処理の他のタスクに影響ないかもしれないけど、固有表現認識には問題なりやすいです。
例としては
昨日は吉川美南駅で...
という固有表現認識タスクがあります。吉川美南を「駅」として認識したいです。
普通のLSTMだと、「昨日」「は」の文脈で吉川美南が「人」として認識されるかもしれないです。
この時Bi-LSTMを使うと、認識精度は向上できます。
Bi-LSTM(Bidirectional LSTM)は双方向LSTMと呼ばれるテクニックです。
左から右までLSTMを行って、右から左までLSTMを行って結果を合わせます。両方向の文脈情報を捉えられます。
Bi-LSTMだと、「駅」「で」という情報も使うできるので、吉川美南は駅として認識できる可能性が高くなります。
Bi-LSTMとCRF合わせ
例えば、ある固有表現認識タスクはこういうラベルを使います。
- B-Person(人名のはじめ)
- I-Person(人名の中)
- B-Organization(組織のはじめ)
- I-Organization(組織の中)
- O(その他)
CRFがない時
CRFがない時、Bi-LSTMのアウトプットは単語に対して各ラベルの点数です。
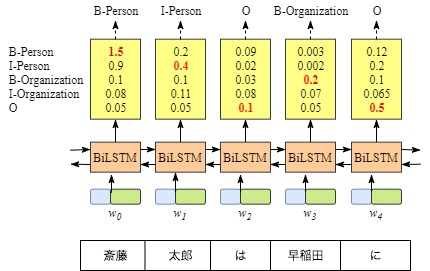
もちろん、一番点数高いラベルを選択できます。この例だと、「斎藤」に対して、「B-Person」の点数は一番高い(1.5)ので、「B-Person」をラベルとして選択できます。
同じように、他の単語を「I-Person」「O」「B-Organization」「O」として選択できます。この例でこの選択は正しいです。
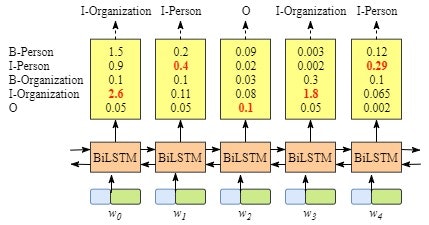
ただし、この例だと、どんな入力があっても、「I-Organization」「I-Person」という順番はありえないです。
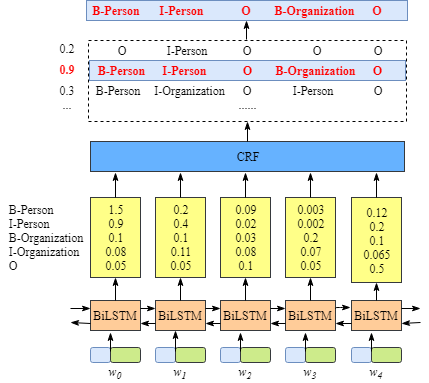
このように、CRFレイヤを加えて、Bi-LSTMのアウトプットを入力して、一番点数高いラベル組み合わせを計算することは必要です
要するに、Bi-LSTMはトークンベクトルの文脈を学習します。CRFはラベル間の依存性を学習します。
Bi-LSTM-CRFの全体像
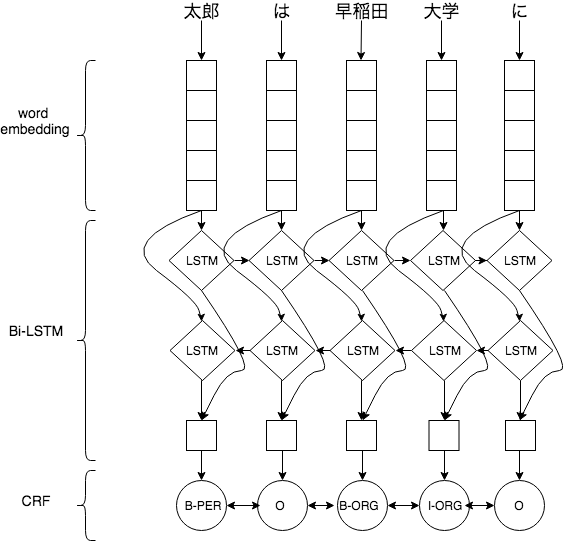
まず入力からword embeddingで単語分散表現を算出します。算出された分散表現はBi-LSTMに入力します。Bi-LSTMは入力文字からベクトルを出力します。このベクトルは文脈を遠慮しているので、各ベクトルにsoftmax分類レイヤを接続して、各ラベルの確率を予測できる。最後にCRF層でラベル間の依存性を考慮してラベルを予測します。
まとめ
以前よくあるパターンはMecabなどツールで文章を形態素解析して、neologdを導入して、足りない部分を辞書自作することです。Bi-LSTM-CRFだと、trainingデータを用意すれば、辞書自作部分はいらなくなって結構楽になるはず。また、辞書と組み合わせて、固有表現認識の精度向上も期待しています。