この記事は ただの集団 AdventCalendar PtW.2019 の7日目の記事です。
昨日はtakatorixさんのGo言語でフレーズ検索を実装してみるでした。
はじめに
ETLネタで被っておりました。
機転を利かせて昨年末のAWS re:Invent 2018で出てきたGlueの上位版のようなAWS Lake Formationのプレビュー申請して内容を変更したりできれば良かったのですが、力量不足だったので気にせず記載します。
せめてGlueを避けて、今更ですがDataPipeline中心の内容で、選択に迷った時の一助になれば幸いです。
AWS Data Pipeline
AWS Data Pipeline とは
ずばりETL(抽出、変換、ロード)を行うAWSのサービスです。
所感ですが、コンポーネントを繋いでいくだけで直感的にわかりやすく、公式のドキュメントを読むだけで大体のことは書いてあるので、使うためのハードルは低いです。
基礎知識
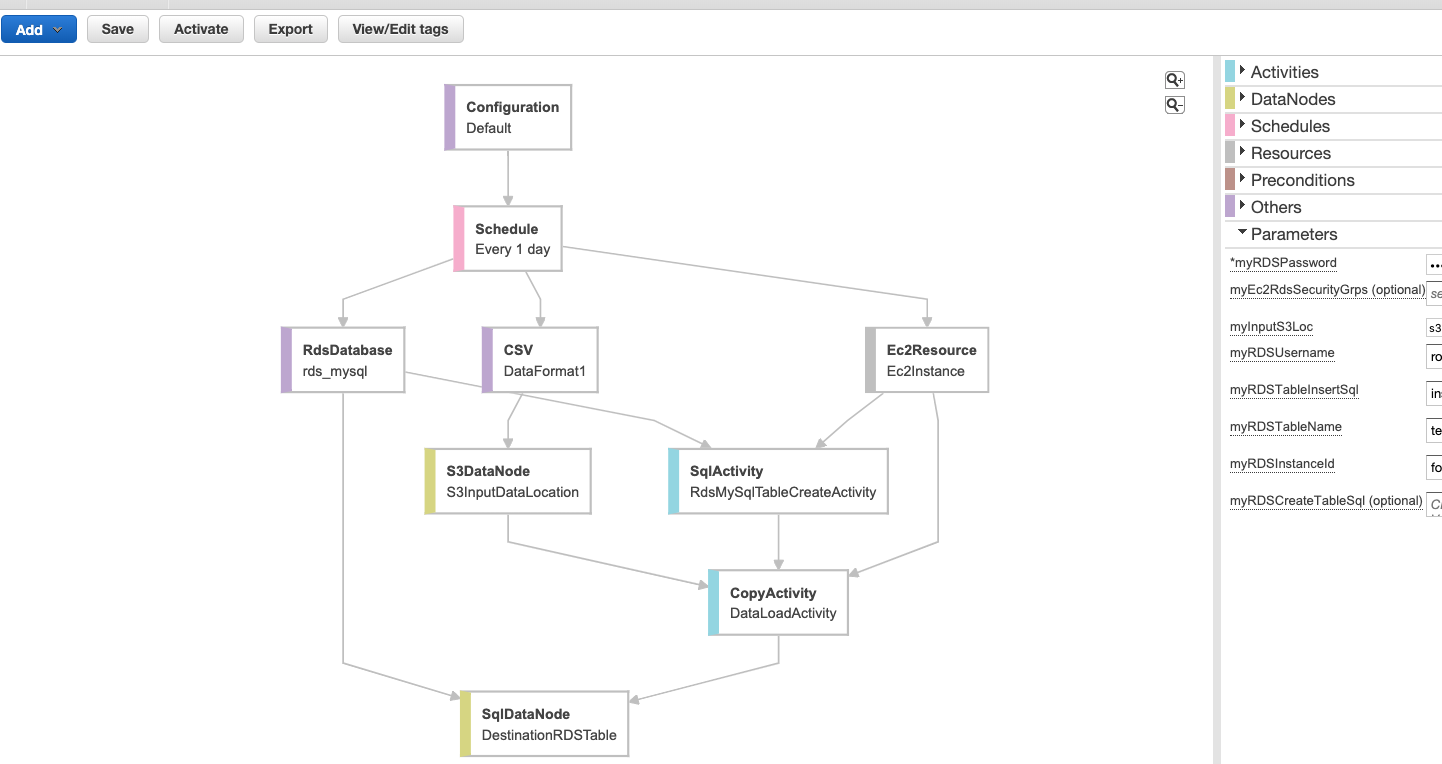
作成されたパイプラインのイメージです。上述はテンプレート(後述)を使って作成したものです。
以下のコンポーネントを定義して構成します。
Activities
データ処理の内容を定義するコンポーネントです。
後述するDataNodesやResoucesを使って実行します。
- ShellCommandActivity
- シェルコマンドを実行する時に使います。実行するシェルを直接書いたり、S3に置いたシェルスクリプトファイルを実行したりします。
- SqlActivity
- SQLクエリを実行します。シェルと同様クエリを定義したり、S3にあるクエリファイルを読み込んで実行したりできます。
- RedshiftCopyActivity
- DynamoDBやS3からAmazonRedshiftにデータをコピーする時に使います。
- 他色々
Data Nodes
入出力で使用するデータの場所やタイプの定義です。
- DynamoDBDataNode
- SqlDataNode
- RedshiftDataNode
- S3DataNode
Schedules
実行スケジュール定義です。特にスケジュールを定義せずにオンデマンドに実行することも可能です。
Resouces
ActivitiesやPreconditionsを実行するコンピューティングリソースで、EC2かEMRクラスターを選択します。
PreConditions
アクティビティを実行するための事前条件を定義できます。
ファイルがある場合に実行するようにしたり、データの存在を確認したりできます。
- DynamoDBDataExists
- S3KeyExists
- ShellCommandPrecondition
- 他
使い方
- 基本的に上述のコンポーネント(他にもあります)を定義して、繋げていくと作成できます。 例えば、S3からRDSにデータを移動させるのであれば、S3とRDSのデータノードを作成して(付随する情報の定義も適宜作成される)、コピーするアクティビティと実行するリソースを作成して繋げると完成。
- ある程度の構成は、用途毎にあらかじめテンプレートとして用意されているので、ベースをテンプレートで作成しておいて編集していくやり方が簡単な気がします。
- テンプレート種類
- Load S3 data into RDS MySQL table (前述のイメージのもの)
- Export DynamoDB table to S3
- Run AWS CLI command
- etc
- テンプレート種類
補足
- RDSでAuroraを使っているのであれば、AuroraはS3のファイルを直接ロードすることができるので、SqlDataNodeなどを作成せずに、SqlActivityにLOAD DATA FROM S3~のクエリを定義して実行することでも同じことができたりします。
- Transformは基本的にシェルスクリプトを書くことになるので、複雑な処理が必要であれば、PySparkやScalaを使えるGlueを使うのが良いです。
まとめ
- Glueとの違いはなんなのかなど、各サービスとの使い分けは公式に記載があります。
- https://aws.amazon.com/jp/glue/faqs/#AWS_Product_Integrations
- ここを見ればこの記事いらない気がするのですが、Apache Spark使うのであればGlueでいいと思います。あとは、定義したリソースのEC2やEMRクラスターに直接アクセスできたり、DataPipelineの方が責任分界点が利用者寄りな感じなので、より自分で制御したい場合はDataPipelineの選択肢もありかなというところでしょうか。
- Glueの場合、RDSをロード先にすると同じパプリックサブネットにする必要があるので、基本的にプライベートに置くであろうRDSにアクセスするためGlueから踏み台サーバーを見れるようにする必要があったりして多少嵌ったことがあったり、他ちょいちょい嵌りどころがある気が。
- ETLという観点から外れますが、GlueのデータカタログはAmazon Athenaでそのまま使えるので、何もしなくてもAthenaのコンソールでGlueのデータベースを選択して参照できて、それだけでも使う価値がありGlueにはプラスアルファな用途もあったりします。
- あとは少量のデータを扱うだけで実行時間が短ければ、制限が15分に拡大したLambdaを使うのも良い気がします。
なんだかまとまりがなくなってしまいましたが、ハードルの低さから、気軽に(料金は気にしない)ETLを試してみたいのであれば、DataPipelineという選択肢を考えるのもありなのかなと思います。
参考
- https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-tech-2015-aws-data-pipeline-52837923
- https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-aws-glue
- https://aws.amazon.com/jp/glue/faqs/#AWS_Product_Integrations
- https://docs.aws.amazon.com/ja_jp/datapipeline/latest/DeveloperGuide/what-is-datapipeline.html
- https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Integrating.LoadFromS3.html
- https://www.qoosky.io/techs/0964aa9fdc