この記事は ただの集団 AdventCalendar PtW.2019 の5日目の記事です。
前回はhajimeniさんのプログラミングする上で避けるべき命名パターン - はじめに。でした。
TL;DR
ElasticsearchをGKE上に構築する方法と、やってみて気づいた注意点を書きます。
また、cerebroでのノード監視と、ESのノード1台を落とした場合に新ノードが作成されること(Self-healing)も検証します。
前提知識
- Elasticsearchを複数ノードで構築したことがある
- GKEのチュートリアルをこなし、Kubernetesでアプリをデプロイしたことがある
- kubectlがローカルで使える
全体構成
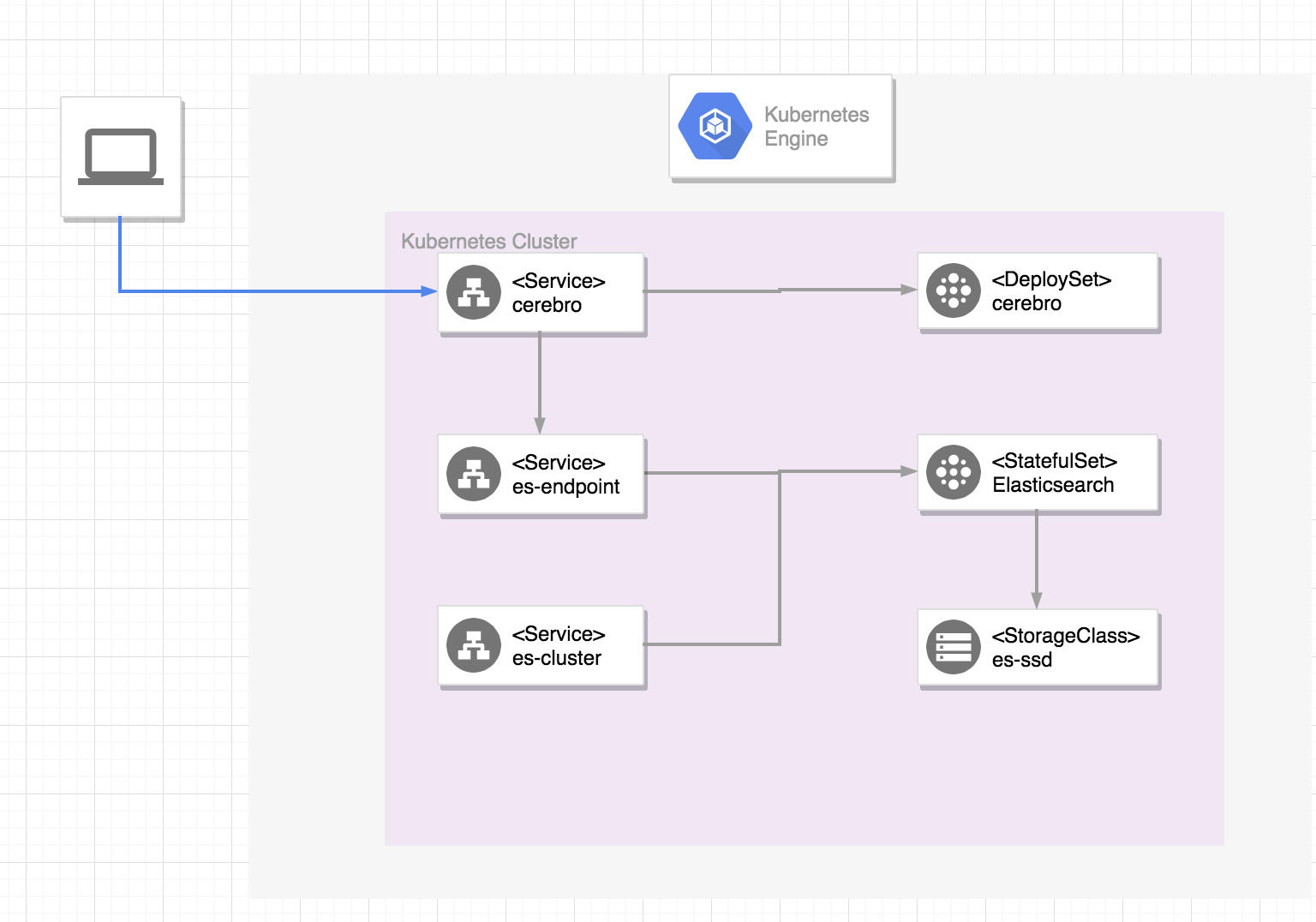
ES構築手順
クラスタの作成
デフォルトのn1-standard-1だとESのメモリ不足になるので、n1-standard-2に変更します。
$ gcloud container clusters create es-cluster --machine-type=n1-standard-2 --num-nodes=2
StorageClassの作成
Elasticsearchのように状態を持つcontainerの場合、containerのデータを永続化する仕組みが必要になります。まずはデータを保存する先としてStorageClassというオブジェクトを作成します。
es-ssdという名前のStorageClassを定義:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: es-ssd
provisioner: kubernetes.io/gce-pd
parameters:
type: pd-ssd
zone: asia-northeast1-b
-
provisioner: kubernetes.io/gce-pd- GCEのPersistent Diskを使用する設定。
-
type: pd-ssd- デフォルトはハードディスクですが、高速化のためGCEの提供するSSDを使用します。
StorageClassオブジェクトの作成:
$ kubectl apply -f storage.yaml
Serviceの作成
ESにHTTPで外部からアクセスするために2つのServiceを定義します。
- ESのノード同士を接続するためのネットワークを提供するes-cluster
- 外部からESのエンドポイントにアクセスするためのes-endpoint
apiVersion: v1
kind: Service
metadata:
name: es-cluster
labels:
service: elasticsearch
spec:
clusterIP: None
ports:
- port: 9200
name: serving
- port: 9300
name: node-to-node
selector:
service: elasticsearch
---
apiVersion: v1
kind: Service
metadata:
name: es-endpoint
labels:
service: elasticsearch
annotations:
cloud.google.com/load-balancer-type: Internal
spec:
type: LoadBalancer
selector:
service: elasticsearch
ports:
- protocol: TCP
port: 9200
-
clusterIP: None- Noneとすることで、HeadlessServiceとして起動します
-
type: LoadBalancer- LoadBalancerにすると、GCPのロードバランサを作成し、外部IPアドレスを露出します。
- annotation:
cloud.google.com/load-balancer-type: Internal- ロードバランサを作成すると外部からアクセスできますが、こちらのannotationを指定すると同サブネットからのアクセスのみ許可します。今回は内部のcerebroからのみアクセスします。
Serviceの作成:
$ kubectl apply -f service.yaml
ElasticsearchのStatefulSetの作成
状態を持つPodをデプロイする場合、StatefulSetというコントローラを使用します。代わりにDeploymentとしてもESのデプロイは可能ですが、Pod再生成時にデッドロックになる挙動のため使用が推奨されていません。
(参考)
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
labels:
service: elasticsearch
spec:
serviceName: es-cluster
replicas: 3
selector:
matchLabels:
service: elasticsearch
template:
metadata:
labels:
service: elasticsearch
spec:
terminationGracePeriodSeconds: 300
# ESを動かすための諸々の初期設定
initContainers:
- name: fix-the-volume-permission
image: busybox
command:
- sh
- -c
- chown -R 1000:1000 /usr/share/elasticsearch/data
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-the-vm-max-map-count
image: busybox
command:
- sysctl
- -w
- vm.max_map_count=262144
securityContext:
privileged: true
- name: increase-the-ulimit
image: busybox
command:
- sh
- -c
- ulimit -n 65536
securityContext:
privileged: true
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.4
ports:
- containerPort: 9200
name: http
- containerPort: 9300
name: tcp
resources:
requests:
memory: 2Gi
limits:
memory: 2Gi
env:
- name: cluster.name
value: elasticsearch-cluster
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: discovery.zen.ping.unicast.hosts
value: es-cluster
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
storageClassName: es-ssd
resources:
requests:
storage: 5Gi
-
name: discovery.zen.ping.unicast.hosts value: es-cluster- ESのdiscoveryはKubernetesではServiceの名前を入れるだけで探すことができました。
-
volumeClaimTemplates:- 先程のStorageClassオブジェクトが作成されただけでは、まだ実態としての容量が確保されていません。volumeClaimTemplatesを使うことで実態としての容量を確保します。
ESのStatefulSetの作成:
$ kubectl apply -f elasticsearch-stateful-set.yaml
cerebroの作成
cerebroはESのノード状態をリアルタイムに監視したり、RESTAPIの実行、GUIでの設定変更が行える便利ツールです。
以下でcerebroのDeploymentとServiceを定義します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: cerebro
labels:
service: cerebro
spec:
replicas: 1
selector:
matchLabels:
service: cerebro
template:
metadata:
labels:
service: cerebro
spec:
terminationGracePeriodSeconds: 300
containers:
- name: cerebro
image: lmenezes/cerebro
ports:
- containerPort: 9000
name: http
---
apiVersion: v1
kind: Service
metadata:
name: cerebro
labels:
service: cerebro
spec:
type: LoadBalancer
ports:
- port: 9000
selector:
service: cerebro
cerebroの作成:
$ kubectl apply -f cerebro.yaml
cerebroのロードバランサのIPを確認:
$ kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
cerebro LoadBalancer 10.51.254.133 34.85.105.164 9000:32654/TCP 7m service=cerebro
es-cluster ClusterIP None <none> 9200/TCP,9300/TCP 9m service=elasticsearch
es-endpoint LoadBalancer 10.51.246.125 10.146.0.21 9200:32653/TCP 9m service=elasticsearch
EXTERNAL-IP:9000でcerebroにアクセス:
ブラウザでhttp://{cerebroのEXTERNAL-IP}:9000
ノード確認
cerebroのテキストボックスにhttp://{es-endpointのEXTERNAL-IP}:9200を入力し、overviewの画面でESのノードを確認
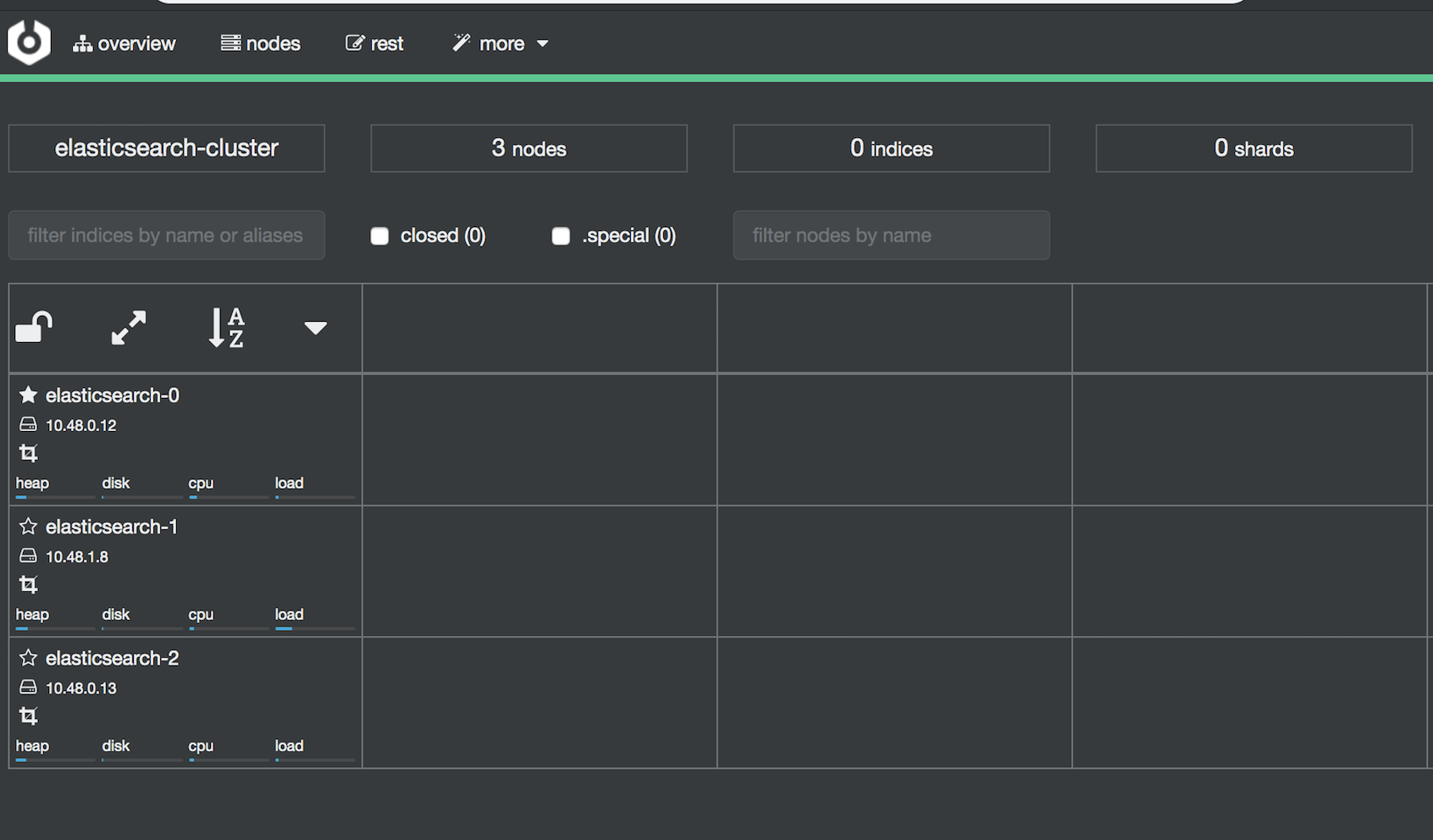
無事ノードを確認できたら完了です。
検証
簡単な検証としてpodを1つ消してもESのアクセスができるか確認します。
まず、適当なindexを作成します。cerebroのメニューのrestから行くとESのAPIが手軽に叩けます。
PUT twitter
以下のように適当なドキュメントを複数個作成します。
POST twitter/_doc
{
"user" : "kimchy",
"post_date" : "2009-11-15T14:12:12",
"message" : "trying out Elasticsearch"
}
cerebroのoverview画面でシャードができているのが確認できます。
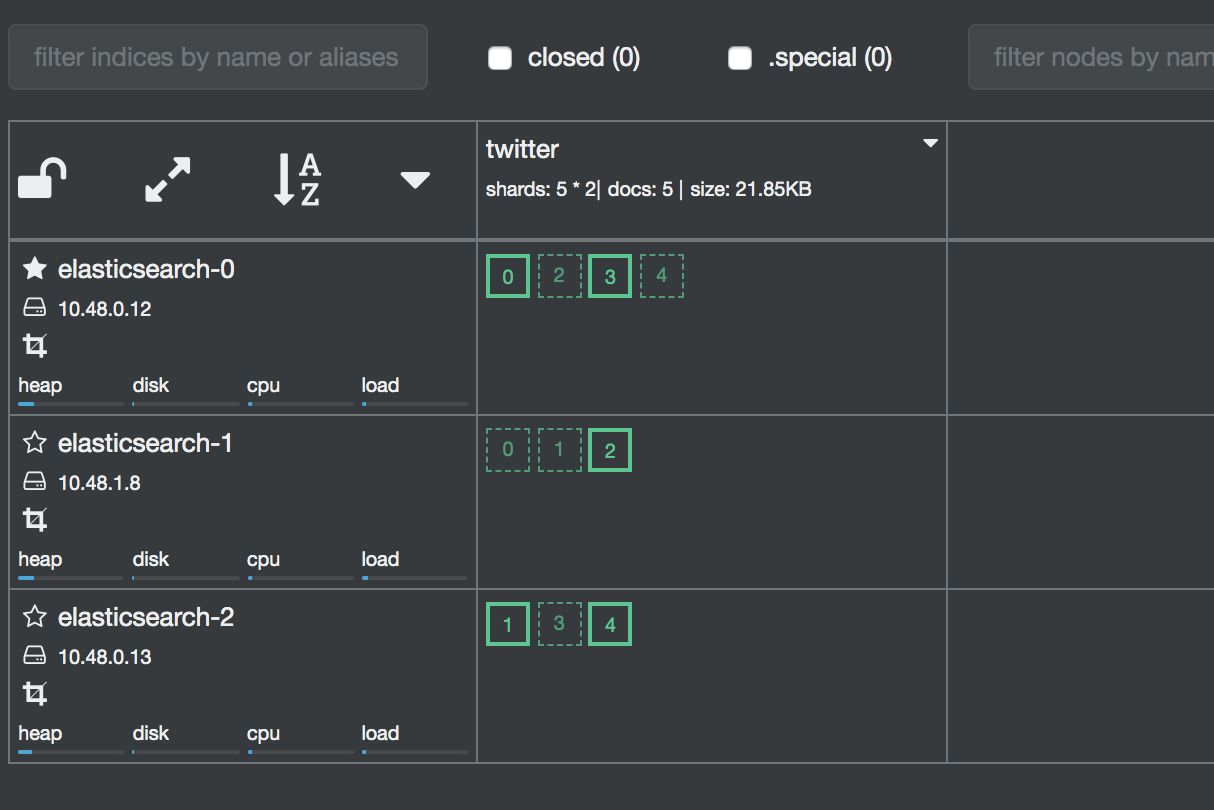
podを1つ落とします。
$ kubectl delete pod elasticsearch-0
cerebroの画面では数秒ヘルスチェックがyellowになります。
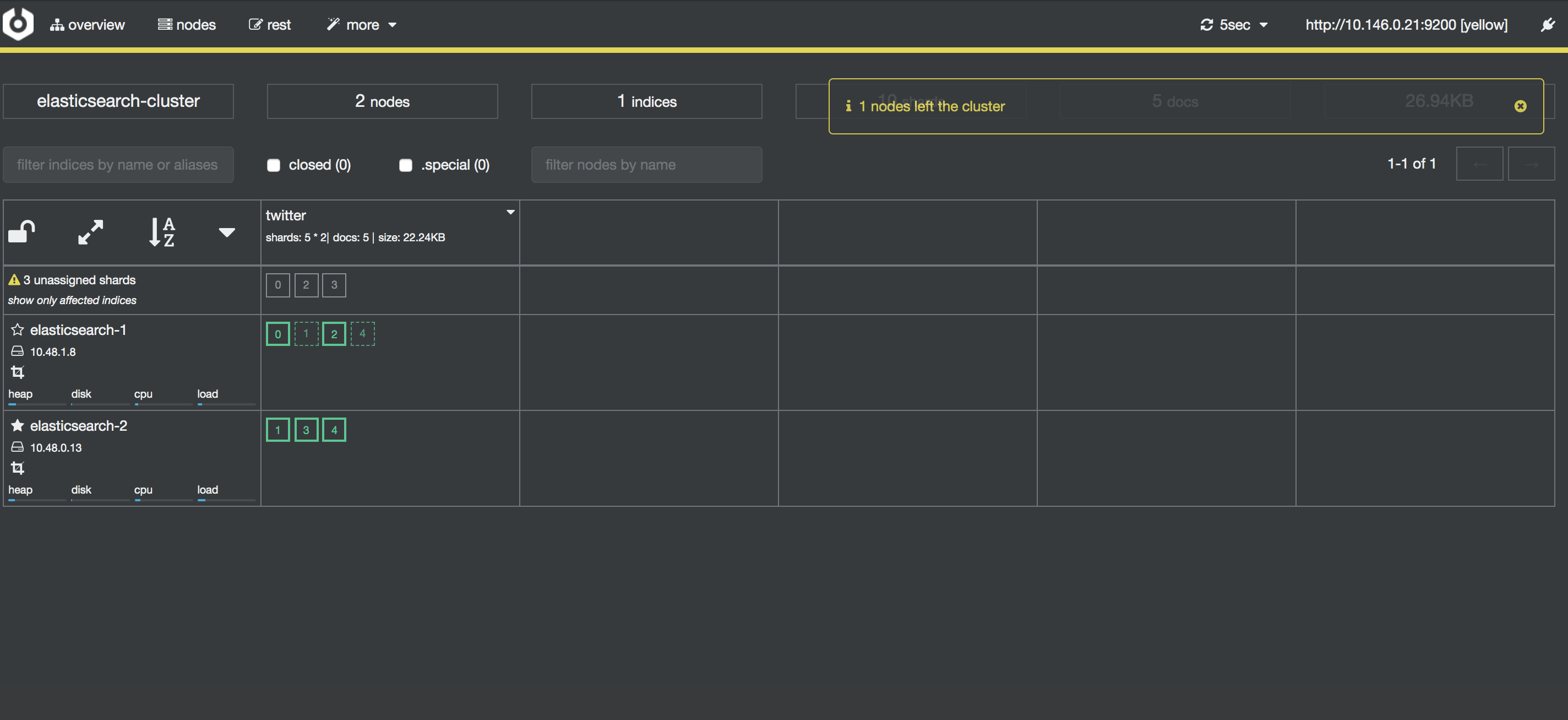
その後待つとelasticsearch-0のノードが復活しgreenに戻ることが無事、確認できます。
まとめ:ESにKubernetesを使用してみて
まだ学習したばかりですが、以下利点があるなと感じました。
- Self-healingやAutoScaleがやりやすい
- デフォルトでSelf-healingの仕組みがあり、Podの水平垂直オートスケールに加えNodeもオートスケールが可能。
- オンラインでnodeのスケールアップやディスク容量リサイズもできる
- 業務で苦労したこれらの問題に対してすでにノウハウがあります。
- ESのzen.discovery設定が楽
- AWSではec2-discoveryのプラグインが必要で、設定にハマりましたが、こちらは不要です。
参考資料
こちらのESのマニフェストファイルを参考にしました。本記事ではより簡易なものに修正し、かつcerebroのPodを追加しています。
A Guide to Deploy Elasticsearch Cluster on Google Kubernetes Engine
やや複雑ですが、公式で出されているkibana+Elasticsearchも参考にしました。
click-to-deploy/README.md at master · GoogleCloudPlatform/click-to-deploy